The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk – on a 4KB page system 5GB should be sufficient but on the Altra’s 64KB system it used up to 9.5GB, including the source directory. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
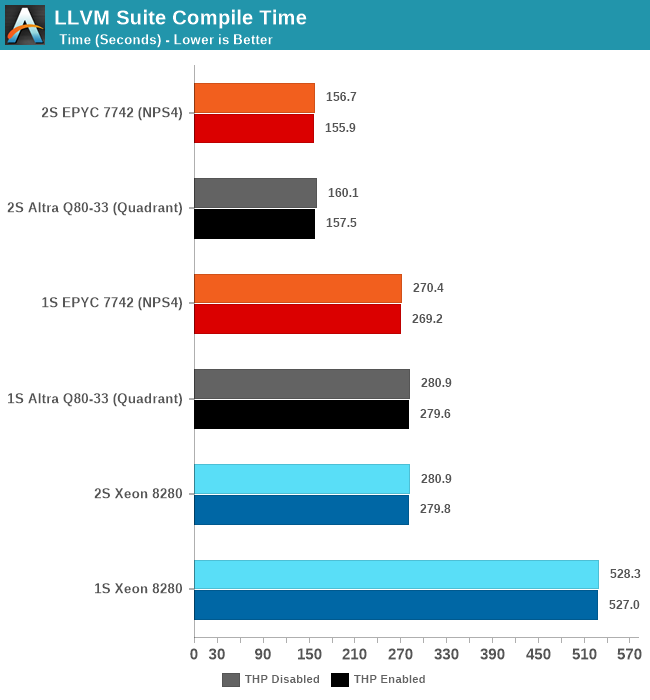
The Altra Q80-33 here performs admirably and pretty much matches the AMD EPYC 7742 both in 1S and 2S configurations. There isn’t exact perfect scaling between sockets because this being a actual build process, it also includes linking phases which are mostly single-threaded performance bound.
Generally, it’s interesting to see that the Altra here fares better than in the SPEC 502.gcc_r MT test – pointing out that real codebases might not be quite as demanding as the 502 reference source files, including a more diverse number of smaller files and objects that are being compiled concurrently.
NAMD
Another rather popular benchmark tool that we’ve actually seen being used by vendors such as AMD in their marketing materials when showcasing HPC performance for their server chips is NAMD. This actually quite an interesting adventure in terms of compiling the tool for AArch64 as essentially there little to no proper support for it. I’ve used the latest source drop, essentially the 2.15alpha / 3.0alpha tree, and compiled it from scratch on GCC 10.2 using the platform’s respective -march and -mtune targets.
For the Xeon 8280 – I did not use the AVX512 back-end for practical reasons: The code which introduces an AVX512 algorithm and was contributed by Intel engineers to NAMD has no portability to compilers other than ICC. Beyond this being a code-path that has no relation with the “normal” CPU algorithm – the reliance on ICC is something that definitely made me raise my eyebrows. It’s a whole other discussion topic on having a benchmark with real-world performance and the balance of having an actual fair and balanced apple to apples comparison. It’s something to revisit in the future as I invest more time into looking the code and see if I can port it to GCC or LLVM.
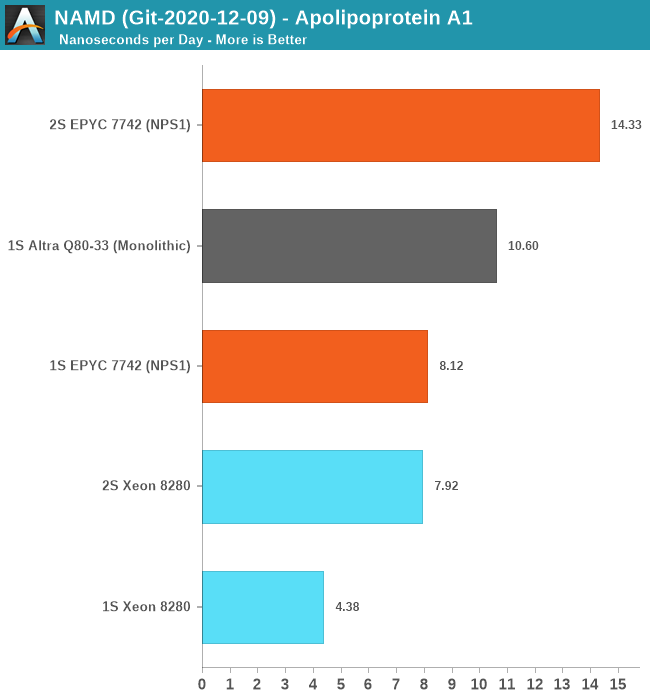
For the single-socket numbers – we’re using the multicore variant of the tool which has predictable scaling across a single NUMA node. Here, the Ampere Altra Q80-33 performed amazingly well and managed to outperform the AMD EPYC 7742 by 30% - signifying this is mostly a compute-bound workload that scales well with actual cores.
For the 2S figures, using the multicore binaries results in undeterministic performance – the Altra here regressed to 2ns/day and the EPYC system also crashed down to 4ns/day – oddly enough the Xeon system had absolutely no issue in running this properly as it had excellent performance scaling and actually outperforms the MPI version. The 2S EPYC scales well with the MPI version of the benchmark, as expected.
Unfortunately, I wasn’t able to compile an MPI version of NAMD for AArch64 as the codebase kept running into issues and it had no properly maintained build target for this. In general, I felt like I was amongst the first people to ever attempt this, even though there are some resources to attempt to help out on this.
I also tried running Blender on the Altra system but that ended up with so many headaches I had to abandon the idea – on CentOS there were only some really old build packages available in the repository. Building Blender from source on AArch64 with all of its dependencies ends up in a plethora of software packages which simply assume you’re running on x86 and rely on basic SSE intrinsics – easy enough to fix that in the makefiles, but then I hit some other compilation errors after which I lost my patience. Fedora Linux seemed to be the only distribution offering an up-to-date build package for Blender – but I stopped short of reinstalling the OS just to benchmark Blender.
So, while AArch64 has made great strides in the past few years – and the software situation might be quite good for server workloads, it’s not all rosy and we’re still have ways to go before it can be considered a first-class citizen in the software ecosystem. Hopefully Apple’s introduction of Apple Silicon Macs will accelerate the Arm software ecosystem.








148 Comments
View All Comments
Andrei Frumusanu - Sunday, January 3, 2021 - link
I actually did test those setups:2S Q64-33 setup: 433.7 SPECint2017 - 341.7 SPECfp2017
Pyxar - Wednesday, December 23, 2020 - link
This is cool and all but what could an arm processor server be used for? Aside from some linux compilations there isn't that much support for arm processors.This is looking a lot like the early days of computing where BeBox was powered by PowerPC cpu, a system looking to find a niche that doesn't exist (yet). It was cool for it's time but very little demand for it.
mode_13h - Wednesday, December 23, 2020 - link
Pretty much everything needed to run modern web services has been ported to ARM. I believe a number of high-profile sites are now using Amazon Graviton2, due to its pricing advantage.As for client computing, the Pi has emerged as a basic, usable desktop platform.
mode_13h - Thursday, December 24, 2020 - link
Also, a couple years ago, Nvidia announced support for their entire software stack on ARM host CPUs. So, I'd say it should also be a decent platform for machine learning, now.Bytales - Wednesday, December 23, 2020 - link
You should have tested some CPU mining bechmarks like Monero's randomX, Wownero's randomwow, Turtle's argon2id Chukwa v2, and DERO's AstroBWT. That would have been interesting as shieeet.Miguelxataka - Sunday, January 3, 2021 - link
7742 (15 months ago release) 225w 67.000 point passmark??? why?? 7702 200w 71.000 points passmark. With 7702 the comparision!!7702 (200w) Zen 2 vs Ampere (250w). 20% less power consumption + with Zen 3 20% extra power consumption =36%?
Where are the power efficiency of the RISC/ARM processors here?
Rance - Friday, July 16, 2021 - link
For the specjbb 2015 data, what was the baseline pagesize set to?4KB/64KB/?
Thanks!
sunwins - Tuesday, October 12, 2021 - link
I guess the speccpu2017 test result is wrong.Maybe there were some problems such as bios version or speccpu software configuration.Reference link:
https://www.spec.org/cpu2017/results/rfp2017.html
https://www.spec.org/cpu2017/results/rint2017.html
AMD 7742 speccpu2017 intrate official value:353 per socket
AMD 7742 speccpu2017 intfp official value:270 per socket
INTEL 8280 speccpu2017 intrate official value:172 per socket
INTEL 8280 speccpu2017 intfp official value:141 per socket
Ampere Q80-33 offcial speccpu2017 intrate value:300 per socket
if you hava any question or updation,please touch 799517515@qq.com。