Intel Core i7-10700 vs Core i7-10700K Review: Is 65W Comet Lake an Option?
by Dr. Ian Cutress on January 21, 2021 10:30 AM EST- Posted in
- CPUs
- Intel
- Core i7
- Z490
- 10th Gen Core
- Comet Lake
- i7-10700K
- i7-10700
CPU Tests: Synthetic and SPEC
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.

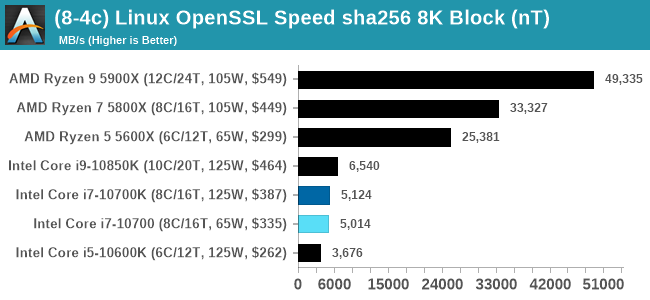
Specifically on the sha256 tests, both AMD and Via pull out a lead due to a dedicated sha256 compute block in each core. Intel is enabling accelerated sha256 via AVX-512 to its processors at a later date.
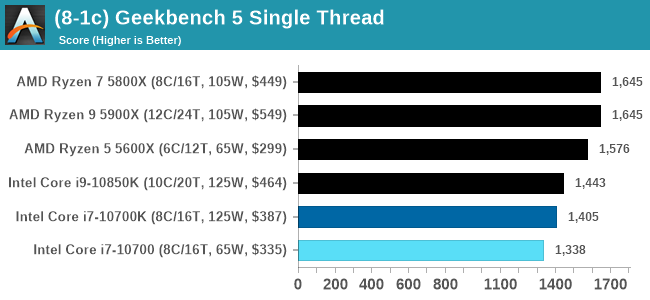
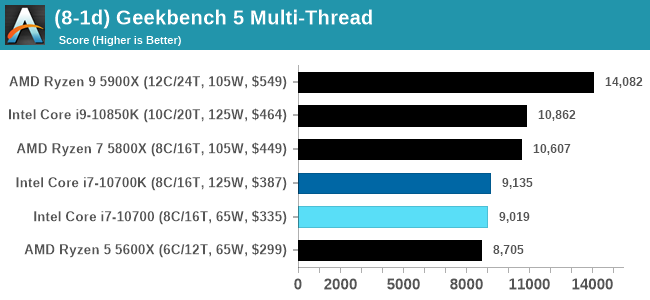
GeekBench 5: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We have both GB5 and GB4 results in our benchmark database. GB5 was introduced to our test suite after already having tested ~25 CPUs, and so the results are a little sporadic by comparison. These spots will be filled in when we retest any of the CPUs.
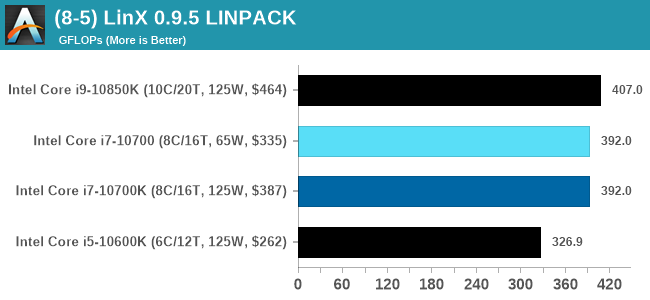
LinX 0.9.5 LINPACK
One of the benchmarks I’ve been after for a while is just something that outputs a very simple GFLOPs FP64 number, or in the case of AI I’d like to get a value for TOPs at a given level of quantization (FP32/FP16/INT8 etc). The most popular tool for doing this on supercomputers is a form of LINPACK, however for consumer systems it’s a case of making sure that the software is optimized for each CPU.
LinX has been a popular interface for LINPACK on Windows for a number of years. However the last official version was 0.6.5, launched in 2015, before the latest Ryzen hardware came into being. HWTips in Korea has been updating LinX and has separated out into two versions, one for Intel and one for AMD, and both have reached version 0.9.5. Unfortunately the AMD version is still a work in progress, as it doesn’t work on Zen 2.
There does exist a program called Linpack Extreme 1.1.3, which claims to be updated to use the latest version of the Intel Math Kernel Libraries. It works great, however the way the interface has been designed means that it can’t be automated for our uses, so we can’t use it.
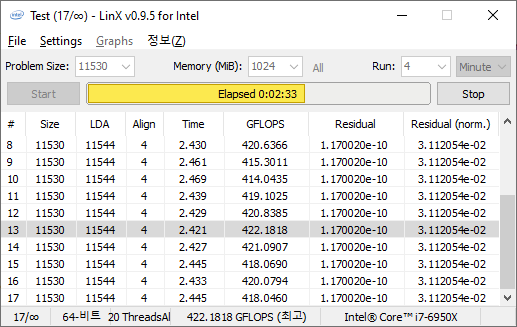
For LinX 0.9.5, there also is a difficulty of what parameters to put into LINPACK. The two main parameters are problem size and time – choose a problem size too small, and you won’t get peak performance. Choose it too large, and the calculation can go on for hours. To that end, we use the following algorithms as a compromise:
- Memory Use = Floor(1000 + 20*sqrt(threads)) MB
- Time = Floor(10+sqrt(threads)) minutes
For a 4 thread system, we use 1040 MB and run for 12 minutes.
For a 128 thread system, we use 1226 MB and run for 21 minutes.
CPU Tests: SPEC
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
For each of the SPEC targets we are doing, SPEC2006 rate-1, SPEC2017 speed-1, and SPEC2017 speed-N, rather than publish all the separate test data in our reviews, we are going to condense it down into a few interesting data points. The full per-test values are in our benchmark database.
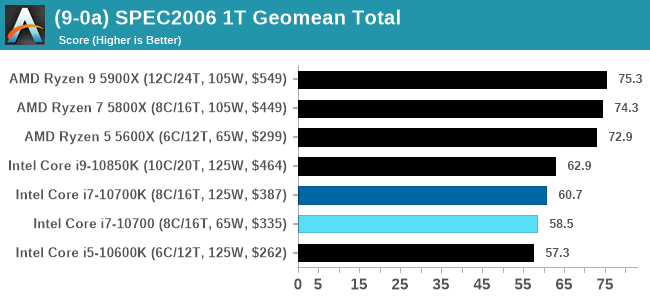
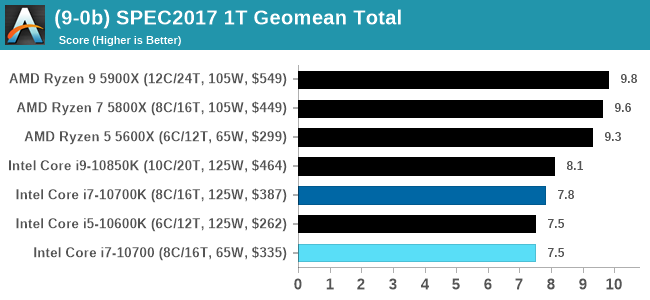
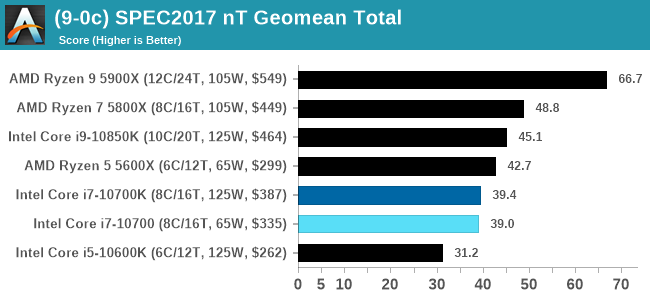
Both of the 8-core Core i7 parts here are handily beaten by AMD's 6-core Ryzen 5 in ST and MT.








210 Comments
View All Comments
Oxford Guy - Sunday, January 24, 2021 - link
This site posted articles about overclocking that were done wildly, without true stability testing and with reckless amounts of voltage and you're going to now pretend that turning on XMP for RAM is some kind of terrible reckless matter?Oxford Guy - Sunday, January 24, 2021 - link
The thing is... if you wish to take a stand about JEDEC and company standards that's fine. Just don't post a lot of nonsensical reasons for it, like "Most users don't know how to plug in a computer so we're going to skip the plug for this review".Oxford Guy - Sunday, January 24, 2021 - link
Personally, here is all I'd say on the subject, were I to be taking your stand:'We use JEDEC standards for RAM speed because those are what AMD, Intel, and other CPU makers use to rate their chips. Anything beyond JEDEC is overclocking and is therefore running out of spec.
Although motherboard makers frequently choose to run CPUs out of spec, such as by boosting to the turbo speech and keeping it there indefinitely, and by including XMP profiles for RAM with lists of 'compatible' RAM running beyond JEDEC, it is our belief that the best place for a CPU's maximum supported RAM speech spec to come from is from the CPU's creator.
If anyone is unhappy about this standard we suggest lobbying the CPU makers to be more aggressive about officially supporting faster RAM speeds, such as by formally adopting XMP as a spec that is considered to be within spec for a CPU.
To compliment the goal of our JEDEC stance, are going to only create reviews using motherboards that fully comply with the turbo spec of vendors and/or disable all attempts by board makers to game that spec. If a board cannot be brought into full compliance we will refuse to post a review of it and any mention of it with the possible exception of a list of boards that run out of spec, are non-compliant.'
Qasar - Sunday, January 24, 2021 - link
Oxford Guy you seem to be quite unhappy about this review, and by other posts, the site as well, so if this site is so bad, WHY do you keep coming here ?Spunjji - Monday, January 25, 2021 - link
He's certainly not his own best advocate in that regard.I'd always defend someone's right to criticise aspects of something they otherwise like, but sometimes it goes a bit far.
Oxford Guy - Monday, January 25, 2021 - link
'but sometimes it goes a bit far.'Extreme vagueness + ad hom = extra fail.
Spunjji - Wednesday, January 27, 2021 - link
@Oxford Guy - 🙄1) That wasn't an ad-hominem - if you're going to do the "master debater" thing, at least learn to distinguish between commentary on the person and their argument.
2) Re: "extreme vagueness" - that was my personal opinion stated as a colloquialism. I don't owe anyone an annotated list of every comment you made, metric measurements of precisely how far they went, an objectively-defined scale of how far is too far, and a peer-reviewed thesis on the precise moment at which you exceeded that point.
Oxford Guy - Monday, January 25, 2021 - link
Ad hom... how unsurprising.To answer your question — This site is not bad. This site is good because people are able to give their honest opinions instead of living in a disgusting echo chamber like on ArsTechnica or Slashdot.
Perhaps that's where YOU should go instead.
Qasar - Tuesday, January 26, 2021 - link
why would i go there ? this site is top notch when it comes to reviews and comp hardware news. "This site is good because people are able to give their honest opinions " yes, but sometimes, some go to far with the whining and complaining :-)trenzterra - Friday, January 22, 2021 - link
Would be good if we could have some temperatures to compare as well. I used to buy the mid-end non-K Intel CPUs since I don't overclock but I always ended up with temperatures about 10 degrees higher than what most people report. With my latest build (ok, not that new now that it's actually a i5-6600k), I went for the K variant and temperatures are much better and in line with what most users report.