MLPerf Releases Official Results For First Machine Learning Inference Benchmark
by Ryan Smith on November 6, 2019 1:01 PM EST- Posted in
- GPUs
- CPUs
- SoCs
- Machine Learning
- MLperf
Since launching their organization early last year, the MLPerf group has been slowly and steadily building up the scope and the scale of their machine learning benchmarks. Intending to do for ML performance what SPEC has done for CPU and general system performance, the group has brought on board essentially all of the big names in the industry, ranging from Intel and NVIDIA to Google and Baidu. As a result, while the MLPerf benchmarks are still in their early days – technically, they’re not even complete yet – the group’s efforts have attracted a lot of interest, which vendors are quickly turning into momentum.
Back in June the group launched its second – and arguably more interesting – benchmark set, MLPerf Inference v0.5. As laid out in the name, this is the MLPerf group’s machine learning inference benchmark, designed to measure how well and how quickly various accelerators and systems execute trained neural networks. Designed to be as much a competition as it is a common and agreed upon means to test inference performance, MLPerf Inference is intended to eventually become the industry’s gold standard benchmark for measuring inference performance across the spectrum, from low-power NPUs in SoCs to dedicated, high-performance inference accelerators in datacenters. And now, a bit over 4 months after the benchmark was first released, the MLPerf group is releasing the first official results for the inference benchmark.
The initial version of the benchmark, v0.5, is still very much incomplete. It currently only covers 5 networks/benchmark, and it doesn’t yet have any power testing metrics, which would be necessary to measure overall energy efficiency. None the less, the initial version of the benchmark has attracted a significant amount of attention from the major hardware vendors, all of whom are keen to show off what their hardware can do on a standardized test, and to demonstrate to clients (and investors) why their solution is superior. In fact, the nearly 600 submissions for the first official round of benchmarking was well above what the group itself was unofficially expecting for a brand-new benchmark (new industry benchmarks typically take a while to become established), underscoring how important MLPerf is for an industry that expects the multi-billion-dollar market for inference hardware to continue to grow at a rapid pace.
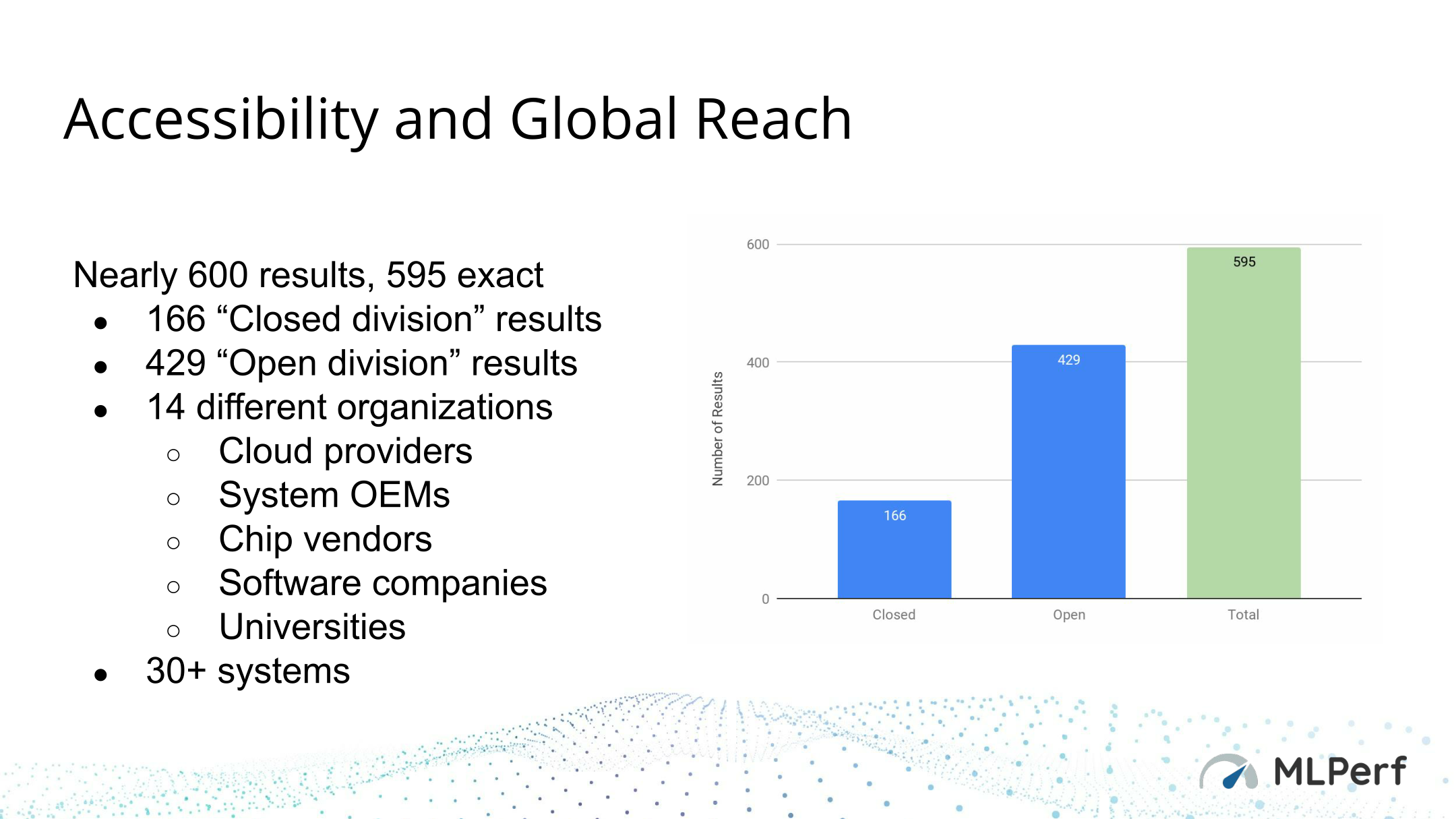
With the first round of submissions now complete, the MLPerf group is now publishing their official results for Inference v0.5, and most (if not all) of the major hardware vendors are releasing announcements, statements, or press releases related to the results. Truth be told, with 600 submissions spread over 40 different tests, there’s a lot of cherry-picking that hardware vendors can and will be doing. Narrow down your criteria enough and everyone can find a scenario in which they win, be it total throughput, client vs. server throughput, latency, throughput per accelerator, etc. Which isn’t a dig at the benchmark itself or even the vendors, but it is a reminder that even this initial version is broad enough that it covers a whole lot of use cases, and that with dedicated accelerators in particular, they are often optimized for very specific use cases.
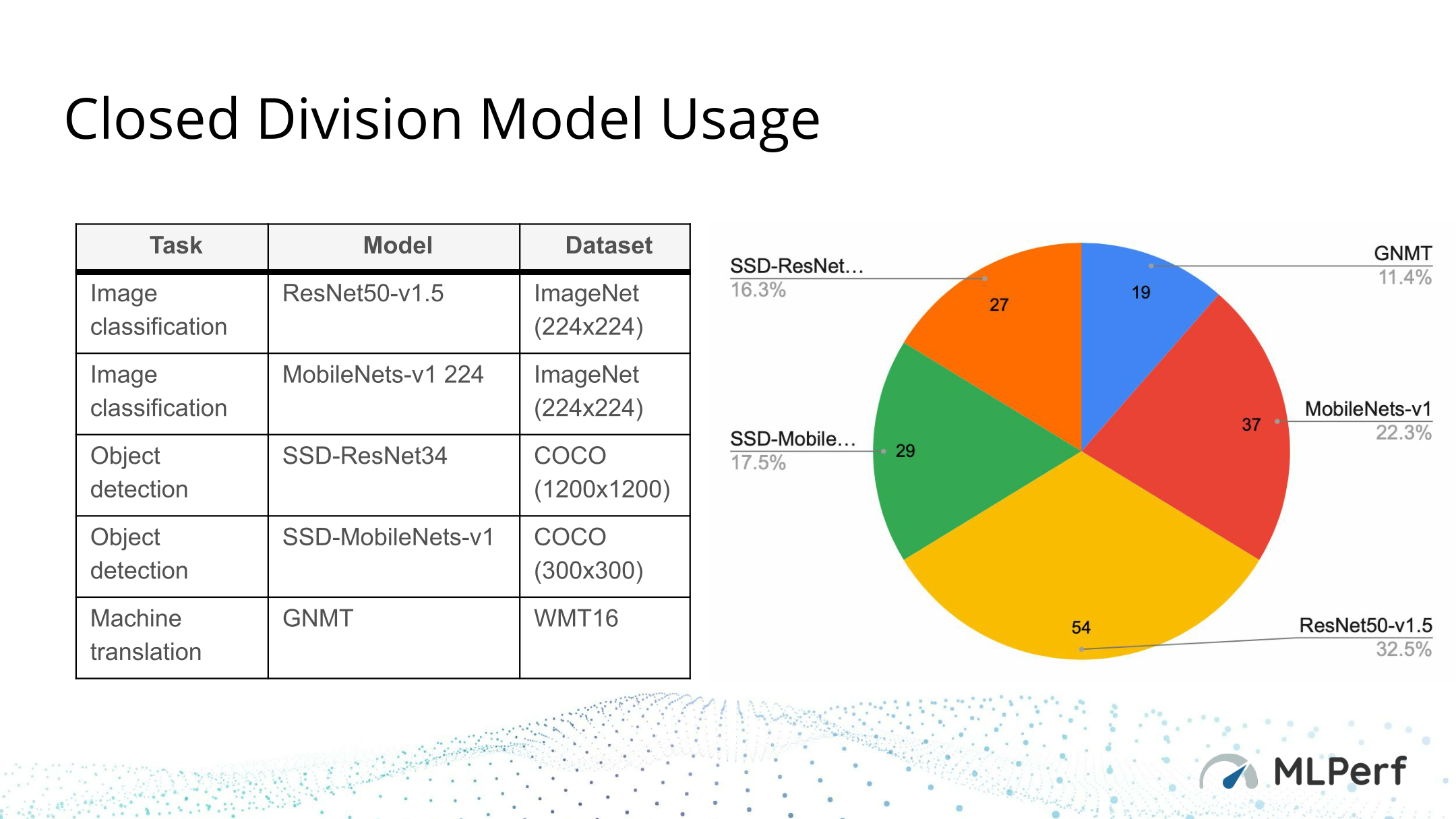
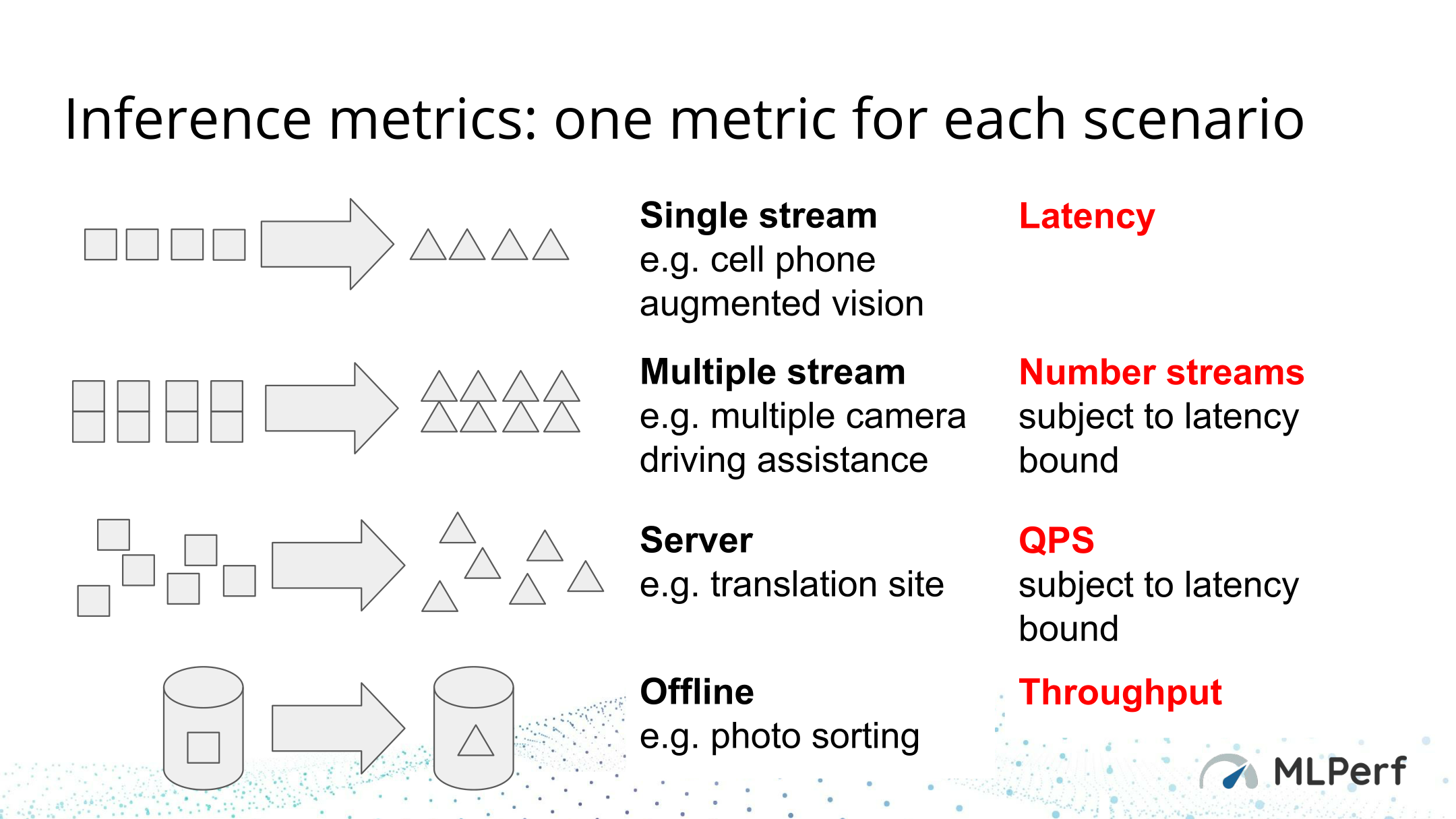
As a quick refresher, MLPerf v0.5 is broken up into 5 benchmarks, with two of those benchmarks essentially being mobile derivatives of their respective master benchmark. From here, the current desktop/server version of the suite covers image classification (ResNet50), object detection (ResNet34), and machine translation tasks (GNMT). Further refining matters, all of the benchmarks are offered with four scenarios: single stream (a client working with one source), multi-stream (a client working with many sources), server (real-time with a focus on queries per second), and offline (a server without real-time constraints). These essentially break up the scenarios into client and server scenarios, and from there into the two most common scenarios for those respective platforms.
Further opening things up, MLPerf offers two “divisions” for testing: the closed division and the open division. The closed division is the group’s apples-to-apples testing, with vendors receiving pre-trained networks and pre-trained weights. Vendors still have some flexibility in quantization, in regards to picking what level of precision to use (so long as the meet the accuracy requirements), but within the closed division their solutions must still achieve mathematical equivalence, and network retraining is specifically disallowed. It is for all practical purposes a test to see how well a platform can execute a client-supplied pre-trained network.

The open division, by contrast, is more open; vendors are allowed to re-train networks as well as do far more extensive quantization work. It is decidedly not apples-to-apples in the same way the closed division is, but the open division is essentially a less structured format that lets hardware vendors show off their solutions and the ingenuity of their teams in the best possible light.
Diving into the results then, MLPerf ended up receiving official submissions across the spectrum, ranging from CPUs and GPUs to FPGAs, DSPs, and dedicated ASICs. As one MLPerf representative noted in our call, the organization essentially received results for every type of processor except for neuromorphic and analog systems. The big groups are of course represented, including NVIDIA’s GPUs, Google’s TPUs, Intel’s CPUs and accelerators, and Habana Labs’ Goya accelerator. There were also some unlikely submissions even in the closed division, including a Raspberry Pi 4, and a preview of Alibaba’s forthcoming HanGuang 800 accelerator.
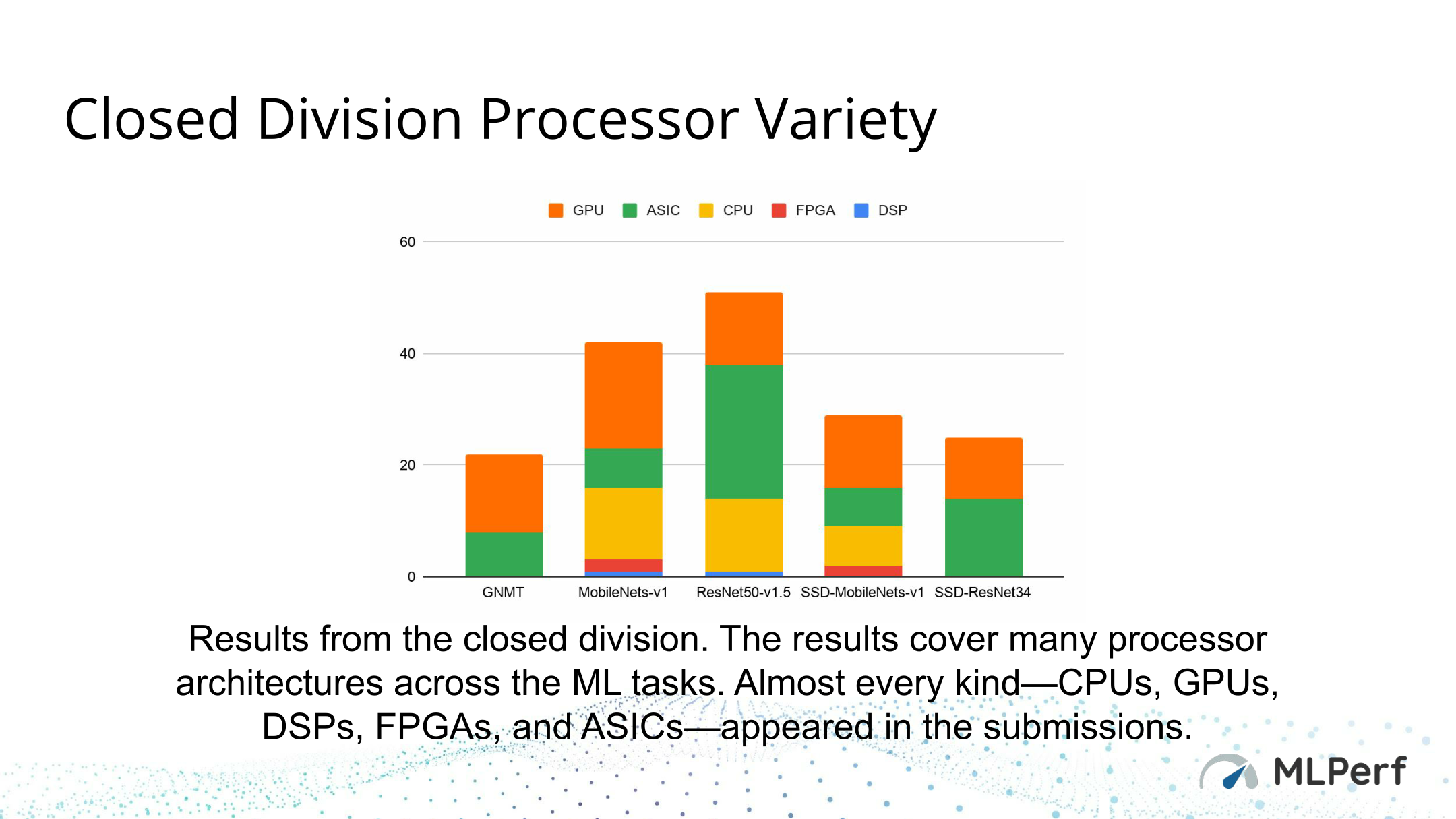
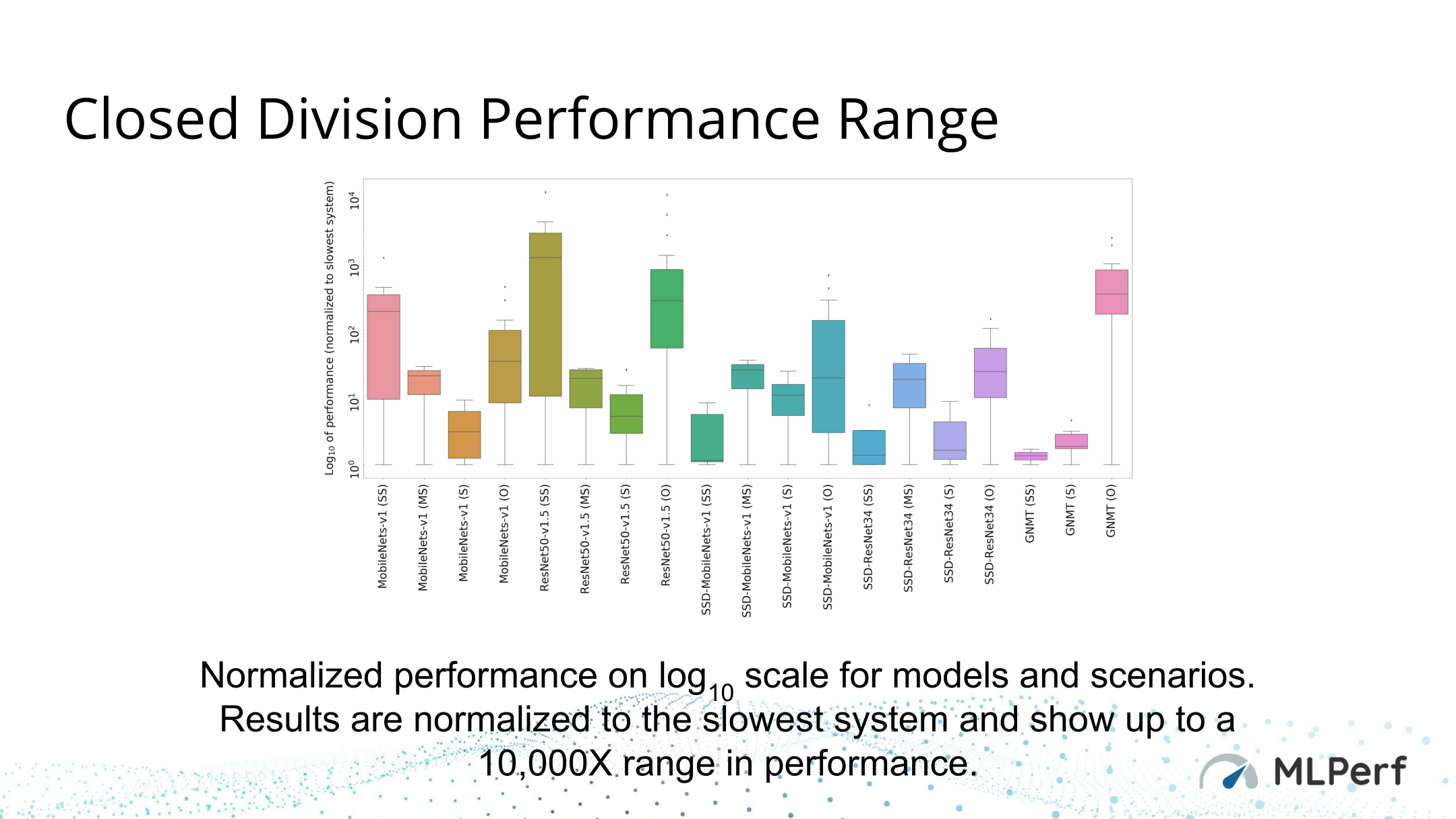
Overall, I’m not going to dissect the results too much here since the wide number of tests means there are an almost infinite number of points of comparison. And perhaps more importantly, the lack of a power test means that energy efficiency can’t be measured at this time. But on the whole, pretty much every vendor can chalk up a win in some category. In offline testing Google saw almost perfect scaling from 1 TPUv3 up to 32, NVIDIA’s Tesla accelerators took the top spots in a few tests, Intel was aces among CPUs, and even Qualcomm’s Snapdragon 855 put up great numbers against the other SoCs in the official results.
Meanwhile the first set of results for MLPerf Inference are not going to be the final word on inference performance. On the development side of matters, the MLPerf group is still working on fleshing out the benchmark to add additional network types, looking at tasks such as speech recognition. As well, the group will be implementing power testing so that everyone can see how efficient their designs are, as power efficiency is frequently the single most important factor in planning a large-scale deployment.
And while these early versions of MLPerf are a bit of a moving target as tests are added and optimized, for the hardware vendors they now know where things stand with their own gear, as well as the competition’s. Even more so than SPEC, the young and open-ended nature of machine learning optimization means that the vendors potentially have a lot of room left to optimize their systems for future tests, as well as to design new hardware that is even better suited to the kind of workloads that customers (many of whom are on the MLPerf committee) are looking to speed up. So now that the first results are out, hardware vendors can focus on the racing aspect and see how they can pull ahead for the next round of official testing.
Finally, on a broader outlook, as the MLPerf Inference benchmark reaches maturity over the coming years (the group isn’t currently estimating when a 1.0 might be ready), it also means that the benchmark will stabilize and become easier for use outside of hardware vendors’ performance labs. The MLPerf group has already commented that they’ll be developing a mobile application to expedite testing of phones and other smart devices, and we’re expecting the desktop benchmarking situation to mature as well. So with any luck, in the not too distant future we’ll be able to roll MLPerf Inference into our own testing, and translate these tests into meaningful results for comparing consumer hardware. Exciting times are ahead!











Source: MLPerf Group








11 Comments
View All Comments
Elstar - Wednesday, November 6, 2019 - link
If they just used ML to find the best ML benchmark, they'd be at 1.0 by now.Amandtec - Wednesday, November 6, 2019 - link
Ha Ha. But what if the process snowballs ? By version 3 it might refuse to open the pod bay doors.ballsystemlord - Wednesday, November 6, 2019 - link
Spelling error:"As one MLPerf representative noted in our call, they organization essentially received results for every type of processor except for neuromorphic and analog systems."
"The", not "they":
"As one MLPerf representative noted in our call, the organization essentially received results for every type of processor except for neuromorphic and analog systems."
ballsystemlord - Wednesday, November 6, 2019 - link
So where are the individual numbers?ballsystemlord - Wednesday, November 6, 2019 - link
I mean per product, of course.Ryan Smith - Thursday, November 7, 2019 - link
Sorry, the URL for the results wasn't available at the time this story was being written.https://mlperf.org/inference-results/
webdoctors - Thursday, November 7, 2019 - link
Thanks. Is there a reason only the Nvidia accelerated machines have results in all columns? I'd imagine all platforms should be able to run all the tests right?Ryan Smith - Thursday, November 7, 2019 - link
It's up to the vendors to decide what tests they wish to submit results for. NVIDIA, presumably, was feeling confident about the flexibility of its wares.mode_13h - Wednesday, November 13, 2019 - link
Perhaps it had more to do with Nvidia being one of MLPerf's "reference" platforms.20x T4's in a single box? Wow, the fan noise has got to be up there with any blade server.
name99 - Thursday, November 7, 2019 - link
"Intending to do for ML performance what SPEC has done for CPU and general system performance"So
- create a target for compiler optimization with little real world relevance AND
- create a pool of internet weirdos who continue to insist that if the results don't match their company favorites then it's a useless benchmark of zero relevance
???
I kid. But sadly, not by much...